


Intra-data center connectivity—linking servers, switches, and storage within a single facility—has seen major changes over the past decade. While Spine-Leaf remains the leading architecture for its scalability and predictable performance, new topologies are emerging to meet the growing demands of Artificial Intelligence (AI), machine learning, and other high-performance workloads.
At the same time, advances in transceiver technology are playing a key role in enabling these new network designs. As data center workloads evolve—especially with AI, disaggregated storage, and real-time analytics—transceivers must deliver faster speeds, longer reach, and greater energy efficiency. These improvements directly influence which topologies are feasible and cost-effective.
Let’s explore where transceiver technology is headed, how it supports evolving topologies, and what’s next for the networks powering modern workloads.
How Is Intra-Data Center Architecture Evolving for AI?
Today’s data center network is split into two fundamental domains:
-
- Front-End Network: This is the conventional network fabric that connects servers and storage to users and applications. It’s primarily east-west traffic (server-to-server) with a final north-south hop to the outside world via edge routers or data center interconnect (DCI) nodes.
-
- Back-End Network: Purpose-built for AI/ML infrastructure, the back-end network forms the backbone of AI cluster topologies—dedicated, high-performance compute fabrics that interconnect GPUs and accelerators. This environment is private, latency-sensitive, and isolated from the public internet, optimized for tightly coupled, high-bandwidth communications.
The rise of back-end networking marks a shift—not just in architecture, but in interconnect requirements. And that’s where pluggable transceivers are undergoing their biggest transformation yet.
What’s the Difference Between Scale-Up and Scale-Out Networks?
1. Scale-Up Network
Scale-Up refers to adding more resources, such as Graphics Processing Units (GPUs) or memory, within a single node or tightly connected system. In AI clusters, it enables low-latency, high-bandwidth communication between GPUs to act as a unified compute resource, like a single “super GPU” often within the same rack or chassis.
The scale-up network historically relied on just copper-based transceivers, both in passive Direct Attach Copper (DACs) cables or with the addition of Active components (AEC/ADAC). At higher data rates of 800G or 1.6T copper-based transceivers might not achieve enough distance or proper cable management capabilities, so optical based transceivers (pluggables, LPO, LRO, etc.) are starting to make their way into this section too.
2. Scale-Out Network
Scale-Out involves connecting multiple compute nodes or GPU clusters across racks or data halls to expand capacity. It supports distributed workloads and requires high-speed optical interconnects to maintain performance across longer distances. Here, scale-out requires longer-reach optical transceivers, so copper-only transceivers are not a real possibility.
The Ultra Ethernet Consortium is actively working to adapt Ethernet standards for these AI workloads, especially around low latency and zero packet loss, which pushes transceiver and system design innovation even further. During March–April 2025, Heavy Reading (now part of Omdia) surveyed 103 service provider professionals worldwide yielding key insights on AI data center growth, network evolution, and optimization. When respondents were asked what network speeds are deployed in their AI/ML data center infrastructure, “the majority (55%) said they were using 400G, and 34% said they were already using 800G”. A small number (22%) are already employing 1.6T or above, providing further evidence that “AI data center deployments are pushing networks speeds more than any other application.”
How Have 400G Transceivers Paved the Way for Next-Gen Deployments?
400G, offered in two key form factors QSFP-DD and OSFP, has been a core technology for the development of intra-data center deployments for the last five years. These two form factors both use 400G commonly in this configuration: 8x56G PAM4 electrical lanes with different combinations of media side options, e.g. copper (Passive and Active DACs) and optical (8x50G, 4x100G, 1x400G, etc). At 400G, the QSFP-DD has gained the most traction/volume o5ffering lower power consumption, high density and backward compatibility with QSFP/QSFP28 transceivers.
A common deployment, especially with the Leaf and TOR (top of rack), is 400G DR4/DR4+ transceivers connecting to 100G single Lambda optics (100G DR or FR depending on the distance) using Single Mode Fiber (SMF). The analogous deployment with Multi Mode Fiber (MMF) would be the 400G SR4.2 to 4x 100G SR1.2 breakout.
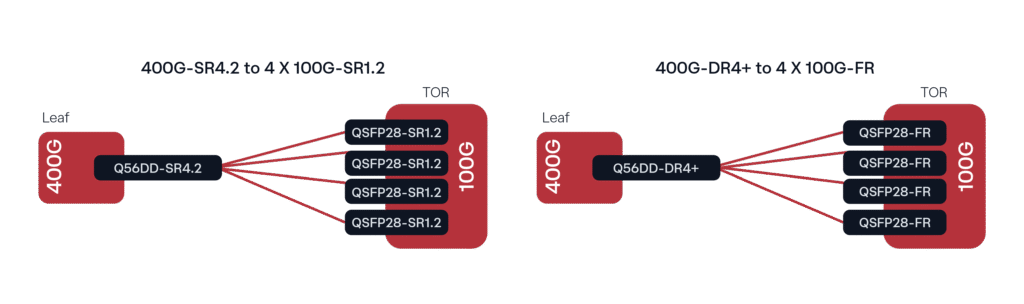
Figure 1. Common 400G Deployment Configurations
Why Is 112G PAM4 a Key Enabler for Emerging Pluggable Solutions?
As electrical lane data rates are increasing, newer form factors such as the QSFP112, QSFP-DD800 and OSFP800 (all with 112G electrical lane capabilities) are becoming part of the data center ecosystem. Bandwidth demand continues to rise, mostly driven by hyperscalers and AI GPU developments, making 800G optics highly prevalent in the network fabric. In a natural progression, as shown in Figure 2, rate per lane increases enable higher bandwidth. 400G transceivers, for example, used to have eight lanes of up to 56G PAM4 to yield 400GbE. Now, 400G pluggables use 4x112G PAM4 electrical lanes (QSFP112/OSFP) and similarly, 800G pluggables now utilize 8x112G PAM4 electrical lanes (QSFP-DD800/OSFP800).

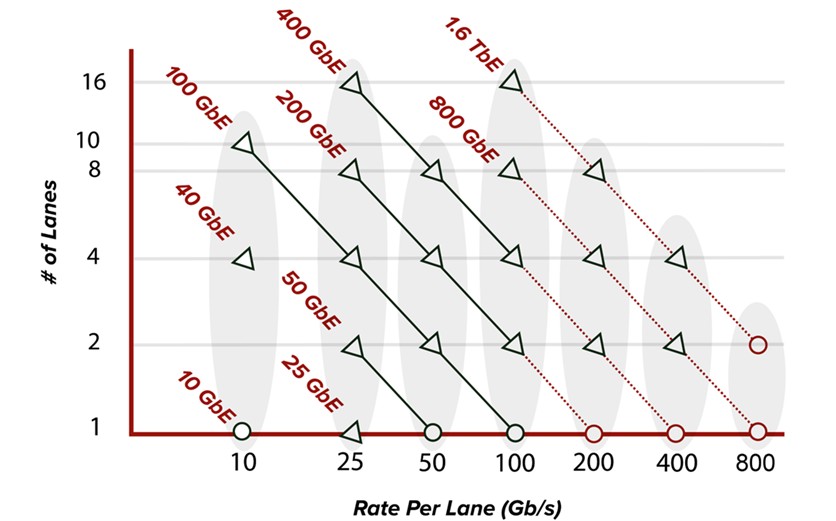
Figure 2. Ethernet Standard Lane Rate Evolution
On the media side, breakout options now expand to also include MPO-16 connectors with 8x100G capabilities and also dual MPO or dual duplex LC/CS that enable 2x400G optical breakouts. Along with the increasing data rates, many new connector types have been introduced to accommodate the increase in applications, including some new Very Small Form Factor (VSFF) types such as CS, SN, MDC, etc. While VSFF connector types have been available for a while now and occasionally used for 400G, they’ve recently become widely adopted for 800G connectivity due to enabling a much higher density per rack unit in the data center cable management needs.
For GPU deployments at 800G, the leading form factor so far has been OSFP800 in a 2x400G breakout configuration to QSFP112 or OSFP (at 400G rates).
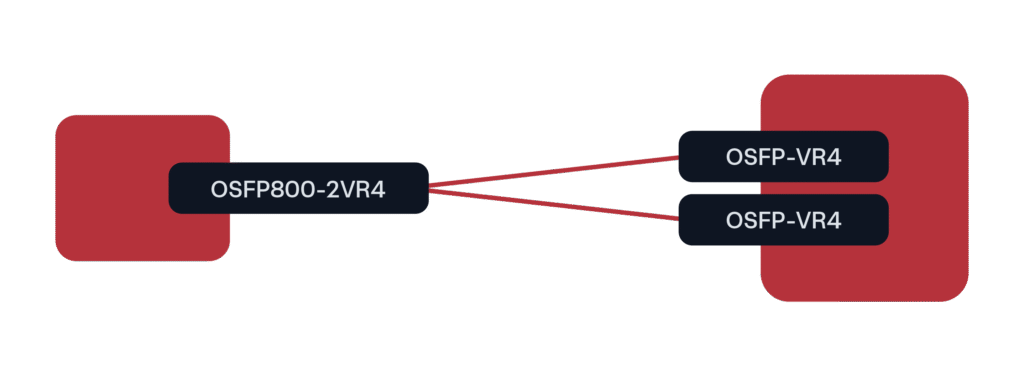
Figure 3. Predominant 800G Deployment Scenario for GPU/AI clusters
QSFP-DD is also available for this breakout configuration but hasn’t had as much traction in hyper-scaler/AI deployments. We do expect the QSFP-DD form factor will still have a place in the Telco/MSO space once they start deploying 800G.
What’s Next for Intra-Data Center Connectivity?
The next generation of optical transceivers for intra-data center applications is being driven by the demand for higher bandwidth and scalability, particularly in AI and GPU-heavy environments. New form factors such as OSFP-XD and QSFP-DD1600 are emerging to support 1.6 Tbps pluggables, with OSFP-XD leading in performance and future scalability. Designed with 16x112G PAM4 electrical lanes and support for 8x224G lanes, OSFP-XD enables not only current 1.6 Tbps optics but also a clear path to 3.2 Tbps. The more flexible thermal management capabilities and higher power capacity make it ideal for high-performance applications and those next-gen data rates.
In addition to new generic transceiver pluggable form factors, technologies like Linear Pluggable Optics (LPO) and Linear Receive Optics (LRO) are gaining traction for reducing power consumption without compromising performance. While Co-Packaged Optics (CPO) promise even greater integration, they still face significant challenges in terms of serviceability, compatibility and ecosystem maturity. As intra-data center connectivity evolves, you can count on Belden and its Precision OT connected brand to continue offering our deep expertise in systems engineering and network integration to help navigate the continued evolution of data centers. From transceiver validation and compatibility to designing custom breakout strategies and managing power and thermal constraints, our team works as an extension of yours—ensuring each deployment is optimized for performance, efficiency, and growth.

