


La connectivité intra-centre de données (reliant serveurs, commutateurs et stockage au sein d'une même installation) a connu des changements majeurs au cours de la dernière décennie. Si Spine-Leaf demeure l'architecture leader pour son évolutivité et ses performances prévisibles, de nouvelles topologies émergent pour répondre aux besoins. demandes croissantes en matière d'intelligence artificielle (IA), l’apprentissage automatique et d’autres charges de travail hautes performances.
Parallèlement, les progrès technologiques en matière d'émetteurs-récepteurs jouent un rôle essentiel dans la mise en place de ces nouvelles conceptions de réseaux. Face à l'évolution des charges de travail des centres de données, notamment avec l'IA, le stockage désagrégé et l'analyse en temps réel, les émetteurs-récepteurs doivent offrir des débits plus élevés, une portée plus étendue et une meilleure efficacité énergétique. Ces améliorations influencent directement les topologies réalisables et rentables.
Explorons où va la technologie des émetteurs-récepteurs, comment il prend en charge les topologies en évolution et quelle est la prochaine étape pour les réseaux alimentant les charges de travail modernes.
Comment l’architecture intra-centre de données évolue-t-elle pour l’IA ?
Le réseau de centres de données actuel est divisé en deux domaines fondamentaux :
-
- Réseau frontalIl s'agit de la structure réseau conventionnelle qui relie les serveurs et le stockage aux utilisateurs et aux applications. Il s'agit principalement d'un trafic est-ouest (de serveur à serveur), avec un saut final nord-sud vers l'extérieur via des routeurs périphériques ou des nœuds d'interconnexion de centres de données (DCI).
-
- Réseau back-end:Conçu spécialement pour l'infrastructure IA/ML, le réseau back-end constitue l'épine dorsale de Topologies de clusters d'IA— des infrastructures de calcul dédiées et performantes qui interconnectent GPU et accélérateurs. Cet environnement est privé, sensible à la latence et isolé de l'Internet public, optimisé pour des communications à haut débit et à couplage étroit.
L'essor des réseaux back-end marque un tournant, non seulement en termes d'architecture, mais aussi en termes d'exigences d'interconnexion. C'est là que les émetteurs-récepteurs enfichables connaissent leur plus grande transformation à ce jour.
Quelle est la différence entre les réseaux Scale-Up et Scale-Out ?
1. Réseau de mise à l'échelle
Le scale-up consiste à ajouter des ressources supplémentaires, telles que des processeurs graphiques (GPU) ou de la mémoire, au sein d'un même nœud ou d'un système étroitement connecté. Dans les clusters d'IA, il permet une communication à faible latence et à haut débit entre les GPU, qui agissent comme une ressource de calcul unifiée, à la manière d'un « super GPU » unique, souvent installé dans le même rack ou châssis.
Historiquement, le réseau à grande échelle reposait uniquement sur des émetteurs-récepteurs à base de cuivre, à la fois dans câbles passifs Direct Attach Copper (DAC) ou avec ajout de composants actifs (AEC/ADAC). À des débits de données plus élevés de 800G ou 1,6T, les émetteurs-récepteurs à base de cuivre peuvent ne pas atteindre une distance suffisante ou des capacités de gestion des câbles appropriées, de sorte que les émetteurs-récepteurs à base optique (enfichables, LPO, LRO, etc.) commencent également à faire leur chemin dans cette section.
2. Réseau évolutif
Le scale-out consiste à connecter plusieurs nœuds de calcul ou clusters de GPU sur des racks ou des salles de données afin d'augmenter la capacité. Il prend en charge les charges de travail distribuées et nécessite des interconnexions optiques haut débit pour maintenir les performances sur de longues distances. Dans ce cas, le scale-out nécessite des émetteurs-récepteurs optiques à plus longue portée ; les émetteurs-récepteurs exclusivement en cuivre ne sont donc pas envisageables.
La Consortium Ultra Ethernet travaille activement à l'adaptation des normes Ethernet à ces charges de travail d'IA, notamment en matière de faible latence et d'absence de perte de paquets, ce qui pousse encore plus loin l'innovation en matière de conception d'émetteurs-récepteurs et de systèmes. Entre mars et avril 2025, Heavy Reading (désormais filiale d'Omdia) a interrogé 103 professionnels des fournisseurs de services du monde entier, recueillant des informations clés sur la croissance des centres de données d'IA, l'évolution et l'optimisation des réseaux. Interrogés sur les débits réseau déployés dans leur infrastructure de centre de données IA/ML, les répondants ont déclaré : « La majorité (55%) ont déclaré utiliser 400 G, et 34% ont indiqué utiliser déjà 800 G. » Un petit nombre (22%) utilisent déjà 1,6 T ou plus, ce qui prouve une fois de plus que « les déploiements de centres de données IA optimisent les débits réseau plus que toute autre application. »
Comment les émetteurs-récepteurs 400G ont-ils ouvert la voie aux déploiements de nouvelle génération ?
Le 400G, proposé sous deux formats clés : QSFP-DD et OSFP, est une technologie essentielle au développement des déploiements intra-centres de données depuis cinq ans. Ces deux formats utilisent couramment le 400G dans cette configuration : 8 voies électriques PAM4 56 G avec différentes combinaisons d'options côté support, par exemple le cuivre.DAC passifs et actifs) et optique (8x50G, 4x100G, 1x400G, etc). À 400G, le QSFP-DD a gagné le plus de traction/volume en offrant une consommation d'énergie plus faible, une densité élevée et une compatibilité descendante avec les émetteurs-récepteurs QSFP/QSFP28.
Un déploiement courant, notamment avec les systèmes Leaf et TOR (top of rack), consiste à connecter des émetteurs-récepteurs DR4/DR4+ 400G à des fibres optiques Lambda simples 100G (DR ou FR 100G selon la distance) via une fibre monomode (SMF). Un déploiement analogue avec une fibre multimode (MMF) serait la connexion 400G SR4.2 vers 4x 100G SR1.2.
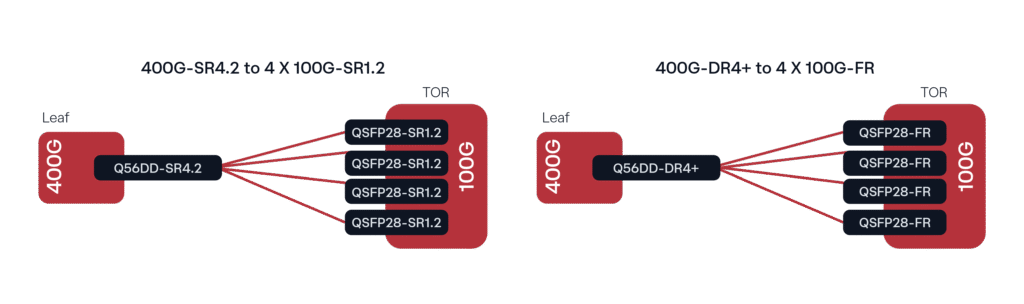
Figure 1. Configurations de déploiement 400G courantes
Pourquoi le 112G PAM4 est-il un élément clé pour les solutions enfichables émergentes ?
Avec l'augmentation des débits de données des voies électriques, de nouveaux formats tels que QSFP112, QSFP-DD800 et OSFP800 (tous dotés de capacités de voies électriques 112G) intègrent l'écosystème des centres de données. La demande en bande passante continue d'augmenter, principalement grâce aux hyperscalers et aux développements des GPU IA, ce qui rend l'optique 800G très répandue dans la structure réseau. Comme le montre la figure 2, l'augmentation du débit par voie permet une bande passante plus élevée. Les émetteurs-récepteurs 400G, par exemple, disposaient auparavant de huit voies allant jusqu'à 56G PAM4 pour atteindre 400GbE. Aujourd'hui, les modules enfichables 400G utilisent 4 voies électriques PAM4 112G (QSFP112/OSFP) et, de même, les modules enfichables 800G utilisent désormais 8 voies électriques PAM4 112G (QSFP-DD800/OSFP800).

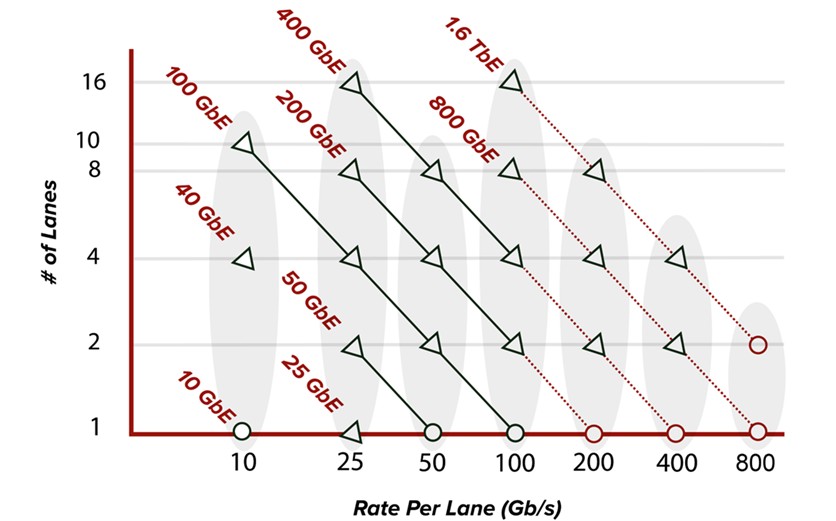
Figure 2. Évolution du débit des voies standard Ethernet
Côté médias, les options de dérivation s'élargissent désormais pour inclure des connecteurs MPO-16 avec des capacités 8x100G, ainsi que des connecteurs double MPO ou double duplex LC/CS permettant des dérivations optiques 2x400G. Avec l'augmentation des débits de données, de nombreux nouveaux types de connecteurs ont été introduits pour répondre à la croissance des applications, notamment des connecteurs à très petit facteur de forme (VSFF) tels que CS, SN, MDC, etc. Si les connecteurs VSFF sont disponibles depuis un certain temps et parfois utilisés pour le 400G, ils ont récemment été largement adoptés pour la connectivité 800G, permettant une densité beaucoup plus élevée par unité de rack pour les besoins de gestion des câbles des centres de données.
Pour les déploiements de GPU à 800G, le facteur de forme principal jusqu'à présent a été OSFP800 dans une configuration de dérivation 2x400G vers QSFP112 ou OSFP (à des débits de 400G).
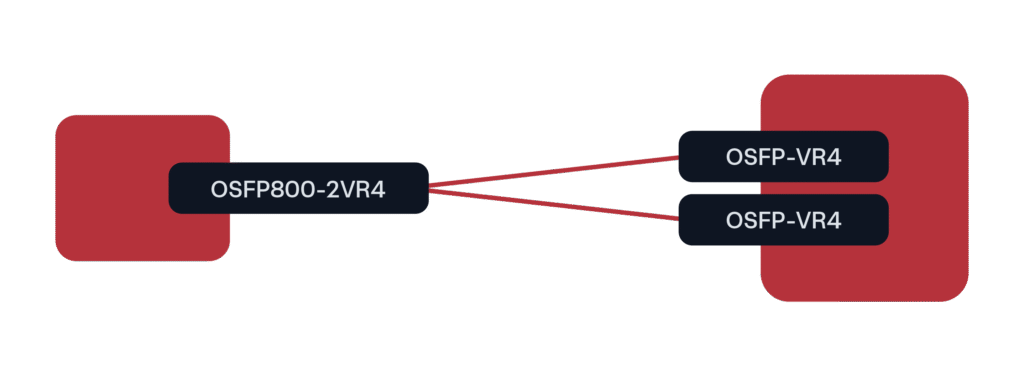
Figure 3. Scénario de déploiement 800G prédominant pour les clusters GPU/IA
Le format QSFP-DD est également disponible pour cette configuration de rupture, mais il n'a pas rencontré autant d'écho dans les déploiements hyperscalers/IA. Nous pensons que le format QSFP-DD conservera sa place dans l'univers Telco/MSO une fois le déploiement du 800G lancé.
Quelle est la prochaine étape pour la connectivité intra-centre de données ?
La nouvelle génération d'émetteurs-récepteurs optiques pour les applications intra-centres de données est stimulée par la demande de bande passante et d'évolutivité accrues, notamment dans les environnements gourmands en IA et en GPU. De nouveaux formats, tels que l'OSFP-XD et le QSFP-DD1600, prennent en charge des modules enfichables à 1,6 Tbit/s. L'OSFP-XD est leader en termes de performances et d'évolutivité. Conçu avec 16 voies électriques PAM4 112G et prenant en charge 8 voies 224G, l'OSFP-XD permet non seulement d'atteindre les 1,6 Tbit/s optiques actuels, mais aussi d'envisager des débits de 3,2 Tbit/s. Sa gestion thermique plus flexible et sa puissance accrue en font un choix idéal pour les applications hautes performances et les débits de données nouvelle génération.
Outre les nouveaux formats génériques d'émetteurs-récepteurs enfichables, des technologies comme l'optique linéaire enfichable (LPO) et l'optique linéaire de réception (LRO) gagnent en popularité pour réduire la consommation d'énergie sans compromettre les performances. Si les optiques co-packagées (CPO) promettent une intégration encore plus poussée, elles restent confrontées à des défis importants en termes de facilité d'entretien, de compatibilité et de maturité de l'écosystème. Face à l'évolution de la connectivité intra-datacenter, vous pouvez compter sur Belden et sa marque Precision OT connected pour continuer à vous offrir notre expertise approfondie en ingénierie système et en intégration réseau afin de vous accompagner dans l'évolution continue des datacenters. De la validation et de la compatibilité des émetteurs-récepteurs à la conception de stratégies de dérivation personnalisées et à la gestion des contraintes énergétiques et thermiques, notre équipe travaille comme une extension de la vôtre, garantissant que chaque déploiement est optimisé pour la performance, l'efficacité et la croissance.

