


Die Konnektivität innerhalb von Rechenzentren – die Verbindung von Servern, Switches und Speicher innerhalb einer einzigen Einrichtung – hat in den letzten zehn Jahren große Veränderungen erfahren. Während Spine-Leaf aufgrund seiner Skalierbarkeit und vorhersehbaren Leistung weiterhin die führende Architektur ist, entstehen neue Topologien, um den wachsende Anforderungen an Künstliche Intelligenz (KI), maschinelles Lernen und andere Hochleistungs-Workloads.
Gleichzeitig spielen Fortschritte in der Transceiver-Technologie eine Schlüsselrolle bei der Ermöglichung dieser neuen Netzwerkdesigns. Angesichts der steigenden Arbeitslasten in Rechenzentren – insbesondere durch KI, disaggregierte Speicherung und Echtzeitanalysen – müssen Transceiver höhere Geschwindigkeiten, größere Reichweite und höhere Energieeffizienz bieten. Diese Verbesserungen haben direkten Einfluss darauf, welche Topologien realisierbar und kosteneffizient sind.
Lass uns erkunden wohin sich die Transceiver-Technologie entwickelt, wie es sich entwickelnde Topologien unterstützt und was als Nächstes für die Netzwerke ansteht, die moderne Workloads unterstützen.
Wie entwickelt sich die Intra-Data-Center-Architektur für KI?
Das heutige Rechenzentrumsnetzwerk ist in zwei grundlegende Bereiche unterteilt:
-
- Front-End-Netzwerk: Dies ist die herkömmliche Netzwerkstruktur, die Server und Speicher mit Benutzern und Anwendungen verbindet. Es handelt sich hauptsächlich um Ost-West-Verkehr (Server-zu-Server) mit einem abschließenden Nord-Süd-Hop zur Außenwelt über Edge-Router oder DCI-Knoten (Data Center Interconnect).
-
- Back-End-Netzwerk: Das speziell für die KI/ML-Infrastruktur entwickelte Back-End-Netzwerk bildet das Rückgrat von KI-Cluster-Topologien– dedizierte, leistungsstarke Rechenstrukturen, die GPUs und Beschleuniger miteinander verbinden. Diese Umgebung ist privat, latenzempfindlich und vom öffentlichen Internet isoliert. Sie ist für eng gekoppelte Kommunikation mit hoher Bandbreite optimiert.
Der Aufstieg der Back-End-Vernetzung markiert einen Wandel – nicht nur in der Architektur, sondern auch in den Verbindungsanforderungen. Und genau hier erleben steckbare Transceiver ihre bisher größte Transformation.
Was ist der Unterschied zwischen Scale-Up- und Scale-Out-Netzwerken?
1. Scale-Up-Netzwerk
Scale-Up bezeichnet das Hinzufügen weiterer Ressourcen, wie Grafikprozessoren (GPUs) oder Speicher, innerhalb eines einzelnen Knotens oder eng verbundenen Systems. In KI-Clustern ermöglicht es eine Kommunikation mit geringer Latenz und hoher Bandbreite zwischen GPUs, die als einheitliche Rechenressource fungieren, ähnlich einer einzelnen „Super-GPU“, die sich oft im selben Rack oder Gehäuse befindet.
Das Scale-up-Netzwerk stützte sich in der Vergangenheit ausschließlich auf kupferbasierte Transceiver, sowohl in passive Direct Attach Copper (DACs)-Kabel oder mit zusätzlichen aktiven Komponenten (AEC/ADAC). Bei höheren Datenraten von 800G oder 1,6T erreichen kupferbasierte Transceiver möglicherweise nicht genügend Distanz oder verfügen nicht über die erforderlichen Kabelmanagementfunktionen, sodass optische Transceiver (Pluggables, LPO, LRO usw.) auch in diesem Bereich Einzug halten.
2. Scale-Out-Netzwerk
Beim Scale-Out werden mehrere Rechenknoten oder GPU-Cluster über Racks oder Rechenzentren hinweg verbunden, um die Kapazität zu erweitern. Es unterstützt verteilte Workloads und erfordert optische Hochgeschwindigkeitsverbindungen, um die Leistung über größere Entfernungen aufrechtzuerhalten. Scale-Out erfordert optische Transceiver mit größerer Reichweite, sodass reine Kupfer-Transceiver keine echte Option sind.
Die Ultra Ethernet-Konsortium arbeitet aktiv an der Anpassung der Ethernet-Standards an diese KI-Workloads, insbesondere im Hinblick auf geringe Latenz und null Paketverluste, wodurch die Innovation im Transceiver- und Systemdesign noch weiter vorangetrieben wird. Im März und April 2025 befragte Heavy Reading (jetzt Teil von Omdia) 103 Fachleute von Dienstanbietern weltweit und gewann so wichtige Erkenntnisse zum Wachstum von KI-Rechenzentren, zur Netzwerkentwicklung und -optimierung. Auf die Frage, welche Netzwerkgeschwindigkeiten in ihrer KI/ML-Rechenzentrumsinfrastruktur eingesetzt werden, antwortete die Mehrheit (551 TP3T), sie würden 400G nutzen, und 341 TP3T gaben an, bereits 800G zu verwenden. Eine kleine Anzahl (221 TP3T) nutzt bereits 1,6T oder mehr, was ein weiterer Beweis dafür ist, dass „KI-Rechenzentrumsimplementierungen die Netzwerkgeschwindigkeiten stärker steigern als jede andere Anwendung“.
Wie haben 400G-Transceiver den Weg für Bereitstellungen der nächsten Generation geebnet?
400G, angeboten in den zwei Hauptformfaktoren QSFP-DD und OSFP, ist seit fünf Jahren eine Kerntechnologie für die Entwicklung von Intra-Data-Center-Implementierungen. Diese beiden Formfaktoren nutzen beide 400G in dieser Konfiguration: 8x56G PAM4 elektrische Leitungen mit verschiedenen Kombinationen von Medienoptionen, z. B. Kupfer (Passive und aktive DACs) und optisch (8x50G, 4x100G, 1x400G usw.). Bei 400G ist der QSFP-DD hat die größte Zugkraft/das größte Volumen erlangt, da es einen geringeren Stromverbrauch, eine hohe Dichte und Abwärtskompatibilität mit QSFP/QSFP28-Transceivern bietet.
Eine gängige Implementierung, insbesondere mit Leaf und TOR (Top of Rack), besteht aus 400G DR4/DR4+-Transceivern, die über Singlemode-Glasfaser (SMF) mit 100G-Lambda-Optiken (100G DR oder FR, je nach Entfernung) verbunden werden. Die analoge Implementierung mit Multimode-Glasfaser (MMF) wäre der 400G SR4.2-zu-4x 100G SR1.2-Breakout.
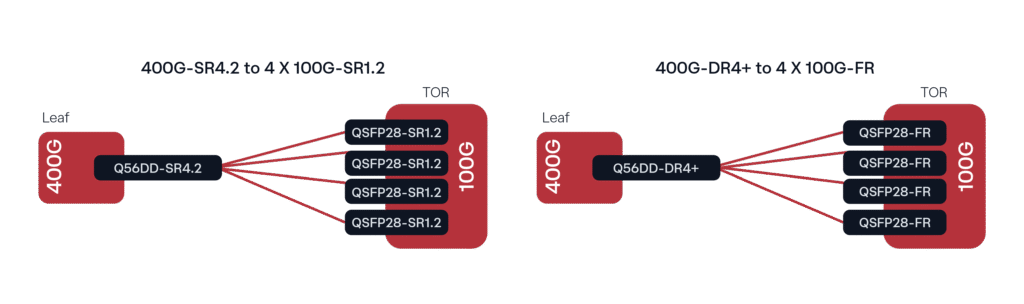
Abbildung 1. Gängige 400G-Bereitstellungskonfigurationen
Warum ist 112G PAM4 ein Schlüsselfaktor für neue steckbare Lösungen?
Mit steigenden Datenraten pro Leitung halten neuere Formfaktoren wie QSFP112, QSFP-DD800 und OSFP800 (alle mit 112G-Fähigkeit für elektrische Leitungen) Einzug in das Ökosystem der Rechenzentren. Der Bandbreitenbedarf steigt weiter, vor allem getrieben durch Hyperscaler und die Entwicklung von KI-GPUs, wodurch optische 800G-Verbindungen im Netzwerk-Fabric stark an Bedeutung gewinnen. Wie in Abbildung 2 dargestellt, ermöglicht eine Erhöhung der Rate pro Leitung in natürlicher Folge eine höhere Bandbreite. 400G-Transceiver beispielsweise verfügten früher über acht Leitungen mit bis zu 56G PAM4, um 400 GbE zu erreichen. Heute nutzen 400G-Steckmodule 4 x 112G PAM4-Leitungen (QSFP112/OSFP) und 800G-Steckmodule 8 x 112G PAM4-Leitungen (QSFP-DD800/OSFP800).

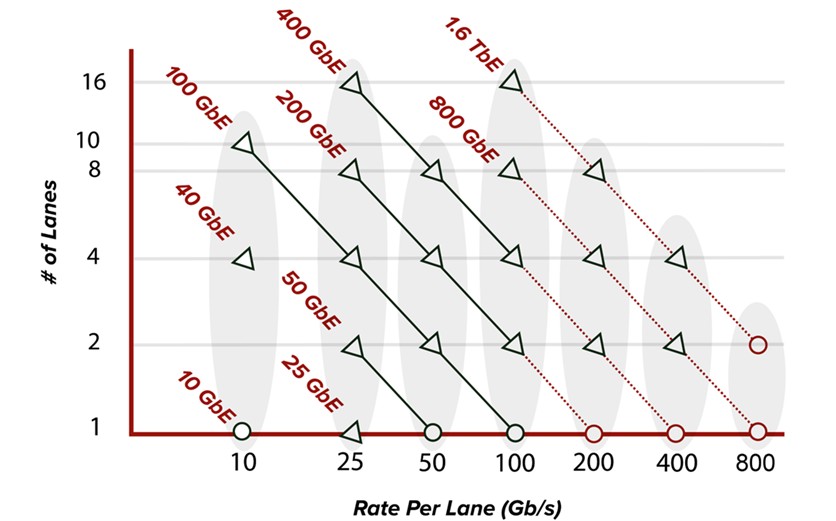
Abbildung 2. Entwicklung der Ethernet-Standard-Lane-Rate
Medienseitig erweitern sich die Breakout-Optionen nun um MPO-16-Stecker mit 8x100G-Kapazität sowie Dual-MPO oder Dual-Duplex LC/CS, die 2x400G optische Breakouts ermöglichen. Mit den steigenden Datenraten wurden viele neue Steckertypen eingeführt, um der zunehmenden Anwendungsvielfalt gerecht zu werden, darunter auch einige neue Very Small Form Factor (VSFF)-Typen wie CS, SN, MDC usw. Während VSFF-Steckertypen schon länger verfügbar sind und gelegentlich für 400G verwendet werden, haben sie sich in letzter Zeit auch für 800G-Konnektivität durchgesetzt, da sie eine deutlich höhere Dichte pro Rack-Einheit im Kabelmanagement von Rechenzentren ermöglichen.
Für GPU-Bereitstellungen mit 800G war der bisher führende Formfaktor OSFP800 in einer 2x400G-Breakout-Konfiguration zu QSFP112 oder OSFP (bei 400G-Raten).
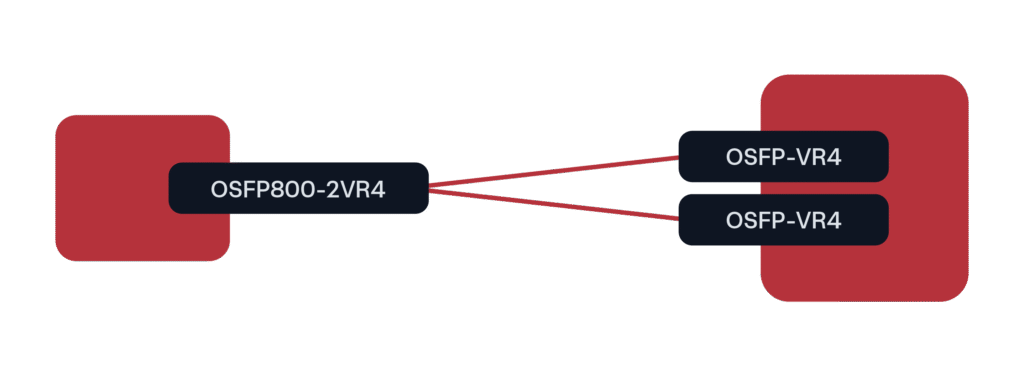
Abbildung 3. Vorherrschendes 800G-Bereitstellungsszenario für GPU/KI-Cluster
QSFP-DD ist auch für diese Breakout-Konfiguration verfügbar, hat sich aber bei Hyperscaler-/KI-Implementierungen nicht so stark durchgesetzt. Wir gehen davon aus, dass der QSFP-DD-Formfaktor auch im Telco-/MSO-Bereich weiterhin seinen Platz haben wird, sobald dort mit der Bereitstellung von 800G begonnen wird.
Wie geht es weiter mit der Konnektivität innerhalb von Rechenzentren?
Die nächste Generation optischer Transceiver für Intra-Rechenzentrumsanwendungen wird durch die Nachfrage nach höherer Bandbreite und Skalierbarkeit vorangetrieben, insbesondere in KI- und GPU-lastigen Umgebungen. Neue Formfaktoren wie OSFP-XD und QSFP-DD1600 unterstützen steckbare 1,6-Tbit/s-Geräte, wobei OSFP-XD hinsichtlich Leistung und zukünftiger Skalierbarkeit führend ist. Ausgestattet mit 16 x 112G PAM4-Lanes und Unterstützung für 8 x 224G-Lanes ermöglicht OSFP-XD nicht nur die aktuelle 1,6-Tbit/s-Optik, sondern auch einen klaren Weg zu 3,2 Tbit/s. Das flexiblere Wärmemanagement und die höhere Leistungskapazität machen es ideal für Hochleistungsanwendungen und die Datenraten der nächsten Generation.
Neben neuen generischen steckbaren Transceiver-Formfaktoren gewinnen Technologien wie Linear Pluggable Optics (LPO) und Linear Receive Optics (LRO) an Bedeutung, um den Stromverbrauch ohne Leistungseinbußen zu senken. Co-Packaged Optics (CPO) versprechen zwar eine noch bessere Integration, stehen aber hinsichtlich Wartungsfreundlichkeit, Kompatibilität und Ökosystemreife noch immer vor erheblichen Herausforderungen. Während sich die Konnektivität innerhalb von Rechenzentren weiterentwickelt, können Sie sich darauf verlassen, dass Belden und seine vernetzte Marke Precision OT weiterhin unsere umfassende Expertise in Systemtechnik und Netzwerkintegration anbieten, um die kontinuierliche Weiterentwicklung von Rechenzentren zu unterstützen. Von der Transceiver-Validierung und -Kompatibilität über die Entwicklung kundenspezifischer Breakout-Strategien bis hin zum Management von Leistungs- und Temperaturbeschränkungen arbeitet unser Team als Erweiterung Ihres Teams und stellt sicher, dass jede Bereitstellung hinsichtlich Leistung, Effizienz und Wachstum optimiert ist.

